제공 :
한빛 네트워크
저자 : Brett Sheppard(@zettaforce)
역자 : 임혜연
원문 :
Get started with Hadoop: From evaluation to your first production cluster
하둡 평가와 첫 클러스터 셋업에 대한 모범 사례

하둡은 성장 중이다. 아파치 소프트웨어 재단(ASF)의 하둡 및 연관된 프로젝트들과 부프로젝트들은 거대한 크기의 다양한 준구조적, 비구조적, 미가공 데이터를 저장, 처리, 분석하기 위한 느슨하게 결합된 통합된 스택의 형태로 성숙했다.
하둡은 비교적 짧은 시간동안 크게 진보했다. 구글 파일 시스템(GFS)과 맵리듀스에 대한 구글의 논문은 데이터 스토리지와 전산 처리 작업을 클러스터에 퍼진 각각의 노드에 같이 배치하는 작업에 대한 영감을 주었다. 그리고, 2006년 초 Doug Cutting은 야후에 입사한 후 아파치 Nutch 검색엔진 프로젝트의 일부였던 분산 컴퓨팅 플랫폼을 적용한 노드 300개로 이루어진 연구용 클러스터를 설치했다.
이제, 가장 큰 생산 클러스터들은 클러스터마다 15페타바이트 스토리지를 가진 4,000개의 노드로 되어 있다. 예를 들어, 야후는 200페타바이트 이상의 데이터를 저장하는 42,000개 이상의 하둡 노드를 운영한다. Hadoop World 2011의 Hortonworks 발표에 따르면, 차세대 맵리듀스 (YARN)가 적용된 하둡 클러스터들은 100,000개 이상의 병렬 태스크와 10,000개 이상의 병렬 잡을 수행할 수 있는 6,000에서 10,000개 사이의 노드까지 늘어날 수 있다.
이 신생 (소프트웨어) 스택 소개글을 쓴 2011년 8월로부터 시간이 지나면서 하둡 설치, 설정, 하둡을 사용한 프로그램 작성은 더 쉬워졌다. 신생 기술에겐 당연하게도, 여전히 할 일은 남아있다. Tom White가 저서 하둡 완벽 가이드: 2판에 언급한 대로,
하둡이 더 널리 적용되기 위해서는 하둡을 한층 더 사용하기 쉽게 만들어야 한다. 이것은 더 많은 도구의 작성, 더 많은 시스템과의 통합, 새롭고 발전된 API의 작성을 수반한다.
이 글은 하둡을 평가하고 첫 클러스터를 배치하려는 조직을 위한 팁과 모범 사례, 주의사항을 제공한다. 이 글은 하둡 분산 파일 시스템(HDFS)과 맵리듀스에 초점을 두었다. 만약 Hive, Pig 혹은 연관 프로젝트와 도구에 대한 상세사항을 찾는다면, 바로 이 글에는 실망하겠지만 더 많은 정보를 찾을 수 있는 링크를 제공하겠다. Cloudera 교육 서비스 부서 임원 Sarah Sproehnle의
Introduction to Apache Hadoop 발표자료를 포함하여, 2012년 2월 28일에 시작한
O"Reilly Strata: Making Data Work의 발표자료들 또한 참조할 수 있다.
독립 실행 혹은 의사 분산 모드로 무료 평가를 시작하라

아직 해보지 않았다면, 무료 하둡 배포판 중 하나를 다운로드받아 설치하여 하둡 평가를 시작할 수 있다.
아파치 하둡 웹사이트에서는 릴리스 0.22 문서에서보다 더욱 자세히 기술된 하둡 릴리스 0.23 싱글 노드 설치 가이드 (역주:실제 링크는 여기인 듯)를 제공한다. 하둡 커뮤니티는 반영되지 않은 몇몇 이전 업데이트가 있지만, 업데이트들을 하둡 버전 1.0으로 묶었다. 예를 들어, 차세대 맵리듀스(프로젝트 이름 YARN)와 HDFS 연합체(엄청나게 많은 수의 파일을 사용하는 클러스터를 지원하기 위해 HDfS 이름공간을 여러 개의 네임노드에 나누는)는 하둡 버전 0.23에는 포함되었으나 하둡 버전 1.0에는 포함되어 있지 않다. 그러니 하둡 버전간 버전 관리를 의식하라.
단일 장비에서의 지역 단독 실행 혹은 의사 분산 모드 실행으로 첫 평가를 시작할 수 있다. 선호하는 리눅스 종류를 고르면 된다.
리눅스나 솔라리스의 대안으로, HDFS와 맵리듀스를 Microsoft Windows 에서 실행하는 선택지가 있다. Microsoft는 Dryad 프로젝트를 중단했고, Sqoop 확장으로하둡에서 SQL Server로의 직접 커넥터를 지원하고, Windows Azure를 위한 하둡 기반 서비스에 착수했고, Hortonworks와 협력 관계를 맺었고, 하둡 지원을 Microsoft SQL Server 2012 버전에 포함하겠다는 계획을 발표했다.
독립 실행 모드에서는 데몬이 실행되지 않는다. 모든 것은 표준 파일 시스템을 사용하는 스토리지를 가지고 하나의 자바 가상 머신(JVM)에서 실행된다. 의사 분산 모드에서는 각각의 데몬은 자기 자신의 JVM에서 실행되지만, 여전히 하나의 장비에서 기본으로 HDFS를 사용하는 스토리지를 가지고 돌아간다. 예를 들어, 나는 하둡 가상 머신을 인텔 프로세서를 탑재한 맥북에서 VMWare Fusion을 통해 Ubuntu 리눅스를 띄우고 거기에 아파치 하둡이 포함된 Cloudera의 배포판(CDH)을 의사 분산 모드로 실행시킨다.
만약 미리 설정되어 있지 않다면, HDFS 복제(replication) 설정값을 기본값 3에서 1로 바꾸는 것을 잊지 말라. 그러면 HDFS의 대안 데이터 노드로 블록을 복제하지 못하기 때문에 발생하는 에러 메시지가 계속해서 나타나지 않을 것이다. 설정 파일들은 "conf" 디렉터리에 있고, XML 형식이다. 복제 파라미터는 dfs.replication이다. 주의: 몇몇 접두사는 하둡 버전 0.22와 0.23 사이에 변경되었다. (그러나 아직 하둡 버전 1.0에 반영되지 않았다). HDFS 접두 이름 변화 설명을 보라.
의사 분산 모드의 기본 평가로도 하둡 데몬에 따라오는, 50030과 50070 포트에서 동작하는 것 같은 웹 인터페이스들을 사용해볼 수 있다. 웹 인터페이스들로 네임노드와 잡트래커 상태를 볼 수 있다. 아래의 스크린샷 예제는 네임노드 웹 인터페이스를 보여준다. 더욱 상세한 리포팅을 위해 하둡은 내장된 Ganglia 연결을 포함한다. 알림 일정을 잡는 데 Nagios를 사용할 수 있다.
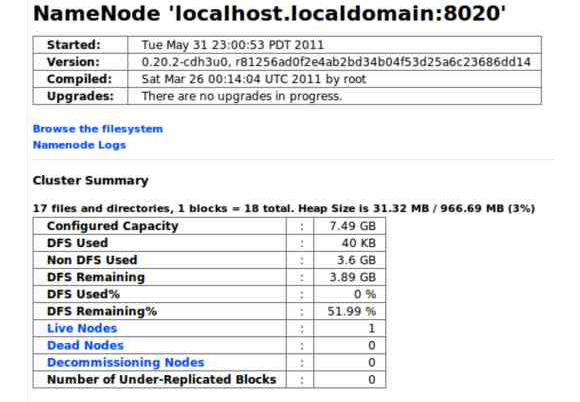
하둡 네임노드 웹 인터페이스는 의사 분산 모드로 동작하는 테스트 클러스터에 대한 하둡 분산 파일 시스템, 노드, 수용능력 개요를 보여준다.
배포판을 고르라
임대된 혹은 정해진 하드웨어상의 멀티노드 클러스터 시험으로 넘어가려 한다면, 하둡 배포판을 골라야 한다. 아파치 하둡은 Common, HDFS, 맵리듀스로 구성된다. 하둡 Common은 하둡 부 프로젝트들을 지원하기 위한 유틸리티 모음이다. 이 유틸리티에는 파일 시스템, 원격 프로시저 호출(RPC), 직렬화 라이브러리가 포함된다. 추가적인 아파치 프로젝트 및 부 프로젝트들은 아파치로부터 제각각 구하거나, 혹은 하둡 소프트웨어 배포판을 패키지하는 Cloudera나 EMS Greenplum, Hortonworks 같은 벤더들로부터 소프트웨어 묶음으로 함께 구할 수 있다.
하둡은 아파치 하둡 커뮤니티에 의해 매우 혁신적으로 진행중인 작업이다. 2011년과 2012년에 추가된 기능에는 차세대 맵리듀스, 네임노드 고가용성에 대한 작업, 클러스터 자원 관리와 맵리듀스 잡 스케줄링의 분리, 모든 하둡 요소의 Avro 데이터 파일 포맷 지원, 메타데이터 관리를 위한 HCatalog가 있다.
상용 배포판을 선택하면 상업적 지원 서비스를 받을 수 있다는 것과 거기 더해 벤더가 연관된 아파치 프로젝트 및 부 프로젝트 내 모든 움직이는 부분 사이의 버전 호환성을 테스트해 준다는 이점이 있다. 이것은 상업적 지원이 있는 Red Hat Linux나 Canonical Ubuntu Linux 간의 선택과 비슷하지만, 확신하건대 하둡이 비교적 최근에 등장했고 많은 숫자의 느슨하게 연결된 프로젝트나 부 프로젝트들이 제공된다는 것을 고려해볼 때 훨씬 중요하다.
지금까지, 아파치 하둡을 포함한 Cloudera 배포판이 가장 완결되고 통합된 배포판이다. 그것은 아파치 하둡, 아파치 Hive, 아파치 Pig, 아파치 HBase, 아파치 Zookeeper, 아파치 Whirr(하둡을 클라우드에서 실행하기 위한 라이브러리), Flume, Oozie, Sqoop을 포함한다. CDH3은 아마존 EC2, Rackspace, Softlayer clouds를 지원한다.
Cloudera 엔터프라이즈는 CDH3에 더해 운영 도구 모음과 생산 지원 서비스를 추가로 제공한다.
Yahoo와 Benchmark Capital은 아파치 하둡 소프트웨어, 하둡 훈련 및 컨설팅 서비스를 제공하는 Hortonworks에 공동투자하기로 했다. Hortonworks 데이터 플랫폼(HDP) 버전 2는 하둡 0.23에 기반하고, 차세대 맵리듀스 및 HDFS 연합체(federation)를 포함한다. 지금까지, 모든 Hortonworks 배포판은 Hortonworks의 Ambari 관리 콘솔까지 포함하여 오픈 소스이다. 2012년 2월과 3월에 Hortonworks는 두 경영진의 역할을 바꾸었고(Rob Bearden은 CEO가 되었고 Eric Baldeschwieler가 CTO가 되었음), 마케팅 부사장으로 John Kreisa를 고용했다(Cloudera에서도 전에 같은 직위에 있었던). 그리고 아파치 하둡 0.23.1과 HDFS 네임노드 고가용성의 출시를 발표했고, Microsoft, Talend, Teradata와의 새롭거나 확장된 협력 관계를 논의했고, Hortonworks의 하둡 배포판을 100% 오픈 소스로 지원하겠다는 약속을 재확인했다.
2011년 6월, Cloudera의 Tom White와 Patrick Hunt는 아파치 Incubator에 Bigtop이란 이름의 새 프로젝트를 제안했다. 그들의 Bigtop 제안서 를 인용하면: "Bigtop은 하둡 생태계의 패키징 개발 및 테스트를 위한 프로젝트이다. 프로젝트의 목적은 다양한 공동체가 개발한 레벨의 결과물을 각각의 프로젝트보다는 시스템 전체에 초점을 맞추어(패키징, 플랫폼, 실행시간, 업그레이드 등) 테스트해보는 것이다."
Bigtop은 아파치 Incubator 단계에 이르렀고, 설치용 바이너리 패키지(RPM과 데비안 패키지)를 제공한다.
EMC Greenplum HD Community Edition 은 HDFS, 맵리듀스, Zookeeper, Hive, HBase를 포함한다. 또한 EMC는 MapR과의 OEM을 발표했으나, 스토리지 벤더 Isilon 인수합병에 따라 MapR과의 협력관계를 경시할지도 모른다.
MapR은 HDFS를 고유 독자 소프트웨어로 대체했다. Hadoop Summit 2011에서, MapR은 comScore와 Narus로부터의 고객 레퍼런스 및 CX, Karmasphere, Think BIg Analytics로부터의 파트너 레퍼런스와 함께
M3 및 M5 Edition의 안정화 버전(general availability, GA)을 발표했다. MapR에 따르면, MapR의 배포판은 HBase, Pig, Hive, Cascading, 아파치 Mahout 기계학습 라이브러리, Nagios 통합, Ganglia 통합을 포함한다. HDFS 대체에 더해, MapR은 맵리듀스 연산 고속화 작업을 했고, 고가용성 옵션을 네임노드와 잡트래커에 추가했다. MapR CEO이자 공동 설립자인 John Schroeder, 마케팅 부사장 Jack Norris와 Hadoop Summit에서 나눈 대화에 따르면 MapR은 네트워크 파일 시스템(NFS)과 NFS 로그 컬렉션, HDFS API를 통한 아파치-표준 HDFS와의 데이터 상호 운용성을 제공한다.
무료 M3 데이션은 MapR 포럼을 통해 이용 가능한 기술 질의응답과 함께 연구용 및 제한 없이 생산용으로 이용 가능하다. 요금 기반 M5 Edition은 상업적 지원 서비스와 함께 미러링, 스냅샷, NFS HA, 데이터 배치 제어 기능을 추가했다. MapR과 Informatica는 2012년 3월 MapR 하둡 배포판에 Informatica 파서를 지원한다고 발표했다.
아파치 하둡의 IBM 배포판(IDAH)은 아파치 하둡, Java 6 SR 8용 32-bit 리눅스 버전 IBM SDK, 하둡용 인스톨러와 설정 도구를 포함한다.
Hadoop Summit 2011의 IBM의 Anant Jhingran의 강연 후 Q&A 세션에서, 나는 Jhingran 박사에게 IBM 배포판의 미래에 대해 물었다. 그는 청중들에게 IBM의 배포판은 기술과 시장이 성숙할 때까지의 임시적인 과정이며, 장기적으로는 하둡의 별도 IBM 배포판을 계속해서 발표하려는 계획은 없다고 설명했다.
IBM은 자신들이 하둡 위에서 동작하는 소프트웨어 패키지들을 만들어냄으로써 하둡을 빅데이터 전략의 초석으로 보고 있음을 시사했다. IBM InfoSphere BigInsights는 데이터 관리, 보안, 개발자 도구, 기업용 통합을 위한 기능들과 함께 구조화되지 않은 텍스트 해석과 인덱싱을 지원한다. IBM은 무료로 다운로드할 수 있는 Biginsights Basic Edition을 제공한다. IBM 고객들은 IBM InfoSphere Streams로부터 나오는 스트리밍 데이터를 분석하도록 BigInsights를 확장할 수 있다. Jeopardy 게임 쇼 경쟁에서, IBM Watson은 하둡을 자연어 해석 지원이 들어있는 정보 가공 작업량을 분산하는 데 사용했다.
Amazon Elastic 맵리듀스 (EMR) 은 아마존 웹 서비스에서 동작하는 데 최적화된 아파치 하둡, Hive, Pig의 독자적인 버전을 개발한다. Amazon EMR은 Amazon Elastic Compute Cloud(EC2)나 SImple Storage Servie(S3)의 웹 규모의 기반 시스템에서 동작하는 임대용(hosted) 하둡 프레임워크를 제공한다.
HStreaming의 배포판은 표준 맵리듀스 배치 처리에 더해 스트리밍 프로세싱 및 실시간 분석 기능을 지원하는 하둡의 독자 버전이다.
하둡 트레이닝을 고려하라
교육 강좌는 하둡 시작과 새 직원 훈련에 도움이 될 수 있다. 필자는 Cloudera의 시니어 강사인 Glynn Durham이 가르치는 이틀짜리
하둡 시스템 관리자 강좌를 들을 기회가 있었다. 그 강좌는 시스템 관리자들과 기업 IT 설계자들에게 추천할 만 했다.
Hortonworks는 지원 서비스 가입과 트레이닝을 제공한다. 하둡 트레이닝과 그 외 지원 서비스를 제공하는 다른 조직을 찾으려면
아파치 하둡 위키 지원 페이지를 방문하라.
Cloudera가 가르치는 하둡 시스템 관리자 강좌를 들으려면 하둡에 대한 선행 지식이 필요하지는 않지만 최소한 기본적 리눅스 명령어를 이해하는 능력은 필요하다. 또한 각각의 하둡 데몬이 자바 프로세스로 동작하기 때문에 약간의 Java 지식도 유익하다. 강좌를 수료한 다음, Cloudera 공인 하둡 관리자가 되기 위한 1시간짜리 시험을 볼 수 있다. 시스템 관리자 수업과 시험은 하둡 클러스터 동작, 계획, 관리, 잡 스케줄링, 모니터링, 로깅에 걸친 범위를 다룬다.
하둡 아키텍처를 설계하라
바로 사용 가능한 클러스터에 일단 몇십 개 이상의 노드를 두기 시작했다면, 각각이 다음의 가장 중요한 데몬에 해당되는 분리된 3대의 엔터프라이즈급 서버에 투자하고 싶을 것이다.
- 네임노드
- 세컨더리 네임노드 (체크포인트 노드)
- 맵리듀스 자원 관리자
이 엔터프라이즈급 서버들은 램 메모리가 많아야 하지만, 자기 자신의 디스크 저장소 용량은 크지 않아도 된다 - 저장소 용량은 데이터노드의 역할이다. 네임노드 메모리는, 충분한 램 용량의 기본선으로 파일당 250바이트에 더해 블록당 250바이트로 생각하라. 블록에 대해, 대다수의 조직들은 기본 블록 크기를 64MB에서 128MB로 바꾸고 싶어하는 데 주의하라. dfs.block.size를 변경하여 블록 크기를 변경할 수 있다.
여러 네임노드 사이에서 이름 공간을 공유하기 위한 HDFS 연합체 옵션은 하둡 0.23 버전부터 시작되었으나, 하둡 버전 1에는 아직 포함되지 않았다. 만약 아주 작은 파일을 굉장히 많이 저장해야만 한다면, HDFS 연합체 사용을 고려하라. 각각의 파일, 디렉토리, 블록은 네임노드 메모리를 150바이트가량 차지하기 때문에 HDFS 연합체를 사용하지 않고는 몇십억개의 파일을 저장할 수 없다.
큰 클러스터에 대해, 네임노드에는 32GB 메모리로 충분하다. 50GB를 훌쩍 넘는 메모리는 네임노드에서 동작하는 자바 가상 머신에서 지나치게 길고 동작에 지장을 주는 시간을 가비지 컬렉션에 사용함으로써 오히려 생산성을 저하시킬 수 있다.
가비지 컬렉션은 JVM이 사용하지 않는 램을 재활용하는 과정을 가리킨다. 시스템 관리자가 통제할 수 있는 옵션이 아주 적으며, 아무 때나 시작될 수 있고, 거의 임의의 시간동안 동작한다. Eric Bruno가
Dr.Dobb"s Report에서 언급한 것처럼, 자바용 실시간 규격(Real-Time specification for Java, RTSJ)은 JVM이 다른 실시간 애플리케이션을 지원하기 좋게 하기까지 하면서 가비지 컬렉션 문제를 해결할 수 있을지도 모른다. Oracle Java Real-Time System, IBM WepSphere Real-Time VM, Timesys RTSJ 레퍼런스 구현이 RTSJ를 지원하지만, 표준으로서는, 특히 리눅스 구현에서는 아직 시험 단계에 머물러 있다.
만약 네임노드가 사라지고 백업이 없다면 HDFS는 쓸 수 없다. HDFS는 데이터 캐싱이 없는 GFS에 기반한다. 네임노드로부터 NFS에 마운트된 디스크 기반 이미지뿐 아니라 적어도 1~2개의 동기화된 복사본을 저장하도록 설계해야 한다. Yahoo와 Facebook에서는 네임노드가 쓰는 실제 데이터를 보유하기 위해 두 개의 NetApp 필터를 사용한다. 이 아키텍처에서는, 두 개의 NetApp 필터는 비휘발성 RAM(NVRAM) 복사를 이용한 HA 모드로 동작한다. HDFS는 이제 네임노드에 고가용성(HA) 즉각적인 장애 복구를 위한 대기(Standby) 네임노드 옵션을 지원한다. 네임노드 HA 브랜치는 HDFS trunk에 병합되었다. 이전 하둡 버전(0.23.1 혹은 그 이전)을 사용하는 조직은
HDFS-1623을 통해 코드를 사용할 수 있다.
잘못 명명된 세컨더리 네임노드(체크포인트 노드로 재명명되고 있는)는 즉각적 장애 복구를 위한 것이 아니고, 네임노드의 네임노드의 재시작 시간을 늘리고 끝내 네임노드의 가용 메모리를 소진시킬 수도 있는 로그가 커지는 것을 방지하기 위한 서버이다. 시작할 때 네임노드는 기본 이미지 파일을 적재하고, 로그 파일에 기록된 최근 변경사항을 적용한다. 세컨더리 네임노드는 네임노드에 대한 주기적인 체크포인트를 수행한다. 그것은 로그 파일의 내용을 이미지 파일에 적용하고, 새 이미지를 생성한다. 체크포인트를 사용하더라도, 클러스터의 재시작은 대형 클러스터에서는 90분 이상이 걸리는데, 네임노드가 시스템을 사용 가능하게 만들기 전 데이터노드 각각의 스토리지 보고를 필요로 하기 때문이다.
하둡 버전 0.21과 그 이후 버전에 백업 네임노드를 사용하는 옵션이 있다. 그러나 MapR 공동 설립자이자 CTO인 M.C.Srivas가
블로그 질의응답에서 설명한 것처럼, 백업 네임노드를 사용하더라도 네임노드가 실패하면 클러스터는 몇 시간이 걸릴 수도 있는 완전한 재시작을 해야 한다. 원래 네임노드를 동기화되었거나 NFS에 마운트된 복사본으로 다시 살리는 것이 백업 네임노드를 사용하는 것보다 나을지도 모른다.
HDFS의 이후 버전들에는 네임노드 고가용성을 얻기 위한 활성-대기(active-standby) 설정으로 묶인 한 쌍의 네임노드(네임노드와 스탠드바이 네임노드) 혹은 Zookeeper 위에 구현된 BookKeeper-기반 시스템과 같은 더 많은 옵션이 있을 것이다. 만약 완전 분산 애플리케이션을 지원해야 한다면,
아파치 ZooKeeper를 고려하라.
YARN(차세대 맵리듀스)부터, 맵리듀스 잡 트래킹은 다음 구성요소 및 부 구성요소를 사용하기 시작했다.

출처: Brett Sheppard가 아파치 하둡 YARN 릴리스 문서에서 따온 그래픽
(1)
자원 관리자(Resource Manager)
1a.
스케줄러: 계층적 큐를 사용하거나, Capacity 스케줄러, 공정(Fair) 스케줄러, 또는 Azkaban이나 Oozie와 같은 작업흐름 도구를 끼워넣을 수 있다.
1b.
애플리케이션 관리자(Applications Manager): 애플리케이션 관리자는 잡 제출 승인, 애플리케이션 마스터를 실행하는 첫 컨테이너 협상, 애플리케이션 마스터 컨테이너 실패시 재시작을 책임진다.
1c.
자원 추적자(Resource Tracker): Application Master 최대 재시도 횟수, 컨테이너 생존 확인 빈도, 노드 관리자(Node Manager)를 죽은 것으로 판단할 때까지 얼마나 기다릴지 등의 설정이 들어 있다.
(2) 하드웨어 노드는 각각 자원 "컨테이너들"(CPU, 메모리, 디스크, 네트워크)을 자원 관리자/스케줄러에게 관리, 모니터, 보고하는 책임이 있는
노드 관리자(Node Manager) 에이전트를 갖는다. 이 컨테이너들은 이전 버전 맵리듀스의 고정 Map과 Reduce 슬롯을 대체한다.
(3) 애플리케이션별, 패러다임-특수적
애플리케이션 마스터(App Mstr)는 애플리케이션 태스크들을 스케줄링하고 실행한다. 만약 클러스터가 맵리듀스와 MPI 같이 여러 패러다임을 사용한다면, 각각은 맵리듀스 애플리케이션 마스터와 MPI 애플리케이션 마스터와 같은 자기 고유의 애플리케이션 마스터를 갖는다.
이름공간(namespace)과 같은 용어처럼, 이 YARN 구성요소들은 ResourceManager, NodeManager, ApplicationMaster로 종종 표기된다. 애플리케이션 마스터가 하나 이상의 하드웨어 노드와 통신할 수 있기 때문에, 모든 노드에 애플리케이션 마스터를 복제할 필요가 없다. 이 차트에서 보여주는 것처럼, 몇몇 노드는 애플리케이션 마스터를 인근 노드(예를 들면 랙 감지를 통해 같은 랙에 있는 노드)에 두고 컨테이너만 가지고 있을 수 있다.
차세대 맵리듀스에 대한 더 많은 정보는
YARN 출시 노트를 참고하라.
지금 세대의 하둡은 IPv6을 지원하지 않는다. IPV6을 사용하는 조직에서는, 개별 노드에 이름을 붙일 때 IP 주소 대신 DNS 서버를 통해 사용되는 장비의 이름을 조사해야 한다. 중국과 같이 빠르게 성장하는 시장에 있는 조직들이 IPv4 주소의 역사적 분배 때문에 IPv6의 조기 수용자가 되는 동안, IPv6은 북미와 다른 지역에서도 더 많은 관심을 갖기 시작했다.
데이터노드는 실패한다고 예상하라. HDFS를 사용하면, 데이터노드가 고장나도 클러스터는 중단되지 않지만 성능은 여전히 동작하는 데이터노드의 여유가 줄어드는 것처럼 유실된 저장공간의 양과 프로세싱 용량에 비례하여 저하된다. 일반적으로, 데이터노드에 RAID를 사용하지 말고, 리눅스 논리 볼륨 마스터(LVM)을 하둡과 사용하는 것을 피하라. HDFS는 여러 노드에 걸쳐 블록을 복제하여 내장된 중복성을 제공한다.
Facebook은 HDFS RAID에 공을 들여왔다. NetApp은 데이터노드에 대한 RAID 사용을 옹호하는 조직이다. 2011년 6월 26일의 NetApp 전략기획 최고 책임자인 Val Bercovici와의 이메일 교환에 의하면: "NetApp의 E-시리즈 하둡 사용자들은 잡과 질의의 완료로부터 데이터 보호를 분리하는 데이터노드에 고도의 공학적인 HDFS RAID 설정을 사용한다. 우리는 대부분의 하둡 ETL 태스크에서, 과거에는 가능하지 않았던 가공(transformation)을 위한 맵리듀스 파이프라이닝을 가능하게 함으로써 향상된 추출과 적재 성능을 목격하고 있다. 롱테일 HDFS 데이터는 또한 훨씬 뛰어난 장기적 HDFS 저장소 효율을 위해서 복제 설정값을 1로 사용하고 RAID로 보호되는 데이터노드로 안전하게 이식될 수 있다."
데이터노드당 스토리지 용량은 증가하고 있기는 하지만 12테라바이트가 일반적이다. Hadoop World 2011의 Hortonworks 발표자료에 의하면, 각각의 데이터노드는 16개 혹은 그 이상의 코어와 48G/96G의 램, 그리고 24TB/36TB 디스크를 갖는다고 한다.
파일 스토리지에 더해, 데이터노드는 30퍼센트 정도의 디스크 용량을 맵리듀스 프로세싱 중간에 생성되는 임시 파일을 위한 빈 공간으로 확보해 두어야 한다. 메모리에 대해서는, 이전 경험법칙은 데이터노드마다 Map이나 Reduce 태스크 슬롯에 1~2GB 메모리를 잡아두는 것이었다. 고정 Map과 Reduce 슬롯을 가상 컨테이너로 대체할 차세대 맵리듀스 / YARN 이 이것을 바꾸었다.
하둡 은 지정한 코덱으로 데이터를 압축하는 옵션을 제공한다. 예를 들어, 페이스북은 대부분의 데이터셋에 대해 압축 인자를 6에서 7 사이로 설정한 gzip 코덱에 의존한다. (2010년 6월 SIGMOD "10 발표자료, "Facebook의 데이터 웨어하우징과 분석 인프라스트럭처")
되도록 데이터노드의 하드웨어 설정을 표준화하라. 여러 종류의 하드웨어에서 실행할 수 있지만, 권한 설정과 조작을 복잡하게 한다. 다른 종류의 하드웨어를 사용하는 노드들이 있다면, 아키텍처는 클러스터보다는 그리드에 가까워진다.
또한, 가상화 사용을 기대하지 말라 - 중대한 성능상 문제가 있다. 하둡은 데이터노드가 자신의 디스크 전체를 사용할 수 있을 때 가장 잘 동작한다. 하둡은 고확장성 기술이지, 고성능 기술이 아니다. HDFS의 특성에 따르면, 데이터 블록과 같이 배치한 프로세싱이 수십, 수백, 수천 개의 독립적인 노드에 퍼지는 것이 낫다. 만약 가상화를 사용해야 할 필요가 있다면, 각 데이터노드 하드웨어 장치에 하나의 VM을 할당하는 것을 고려하라. 이것은 자동화된 권한 설정과 소프트웨어 업데이트와 같은 가상화의 장점을 취하면서 성능 저하를 가능한 한 적게 유지한다.
시스템 관리자를 위한 몇 가지 운영 팁:
- 큰 파일을 지향하라: 너무 많은 작은 크기 파일을 저장하려 하지 말라. 파일당 네임노드 메모리 비용이 발생한다. 몇 개의 작은 파일은 괜찮다 - 수백에서 수천까지도 - 그러나 100메가바이트, 몇 기가바이트, 혹은 그 이상까지 이르는 많은 수의 파일은 사용하지 말아야 한다.
- 설정 파일의 쉼표로 구분된 리스트에는 공백이 없어야 한다: 공백은 에러를 일으킬 수 있다.
- 부하 분산(Load balance): 과부하 상황이거나 부하가 지나치게 낮은 노드를 갱신하기 위해 부하 분산자(load balancer)를 주기적으로 실행시켜라. 재분산 작업은 맵리듀스 잡에 지장을 주지 않는다.
- 랙 감지를 도입하라: HDFS가 가장 가까운 노드를 인식할 수 있게, 랙 감지를 지원하도록 랙 설정을 정의하고 갱신하라. 이것은 랙 감지를 지원하지 않는 Amazon Elastic Compute Cloud에는 적용되지 않음에 주의하라.
- HDFS의 손상을 검사하기 위해 비서비스 시간에 fsck를 매일 실행하라.
- 노드들의 시각을 동기화하라. (기본이지만 잊기 쉬운 과정이다.)
Facebook으로부터, 애플리케이션 운용 엔지니어 Andrew Ryan은 2011년 2월 Yahoo Sunnyvale campus에서 열린 Bay 지역 하둡 사용자 그룹 모임에서 자신이 얻은 교훈을 하둡 클러스터 관리자를 위해 공유했다.
그의 멋진 강연에서 나온 몇 가지 제안사항:
- 클러스터들, 노드들, 그리고 클러스터에서의 각 노드의 역할에 대한 서비스와 자산 관리 플랫폼과 통합된 중앙 레지스트리를 유지하라.
- 망가졌던/망가진 하드웨어는 가장 큰 적이다 - "excludes" 파일은 친구이다.
- 하둡이 하라고 하기 전까지는 ext3 데이터 드라이브에 fsck를 실행시키지 말라.
- 다른 부류의 사용자를 적절한 서비스 수준과 용량을 갖도록 다른 클러스터로 분리하라.
클러스터로는 당연한 말 같지만, 하둡이 여러 개의 데이터 센터로 확장된 클러스터를 구동하는 데 아직 잘 맞지 않기 때문에 위의 교훈은 여전히 상기할 필요가 있다. 야후조차, 최대 비공개영역 하둡 생산 클러스터를 기동할 때 하둡 파일 시스템이나 맵리듀스 잡을 여러 데이터 센터로 분할하지 않았다. Facebook과 같은 조직은 여러 데이터센터에 걸쳐 하둡 클러스터를 연합할 방법을 고려하고 있으나, 그것은 시간 제한 및 일반 규모의 데이터 부하에 도전을 일으킨다. 아키텍처와 엔지니어링 부서 고위 임원인 Mr.Eddie Satterly의
O"Reilly Strata 2012의 Expedia 발표에 따르면, Expedia는 하나 이상의 데이터센터로 확장된 하둡 클러스터를 가동하고 있다.
HDFS로 데이터를 불러오라
클러스터에 저장하려는 데이터의 출처와 관계없이, 입력은 HDFS API를 거친다. 예를 들어, 당신은 로그 데이터 파일을
아파치 Chukwa, Cloudera가 개발한
Flume, Facebook이 개발한
Scribe에 모으고 그 파일들을 HDFS API를 가지고 HDFS 블록 스토리지로 나뉜 클러스터에 넣을 수 있다. 로그 파일과 같은 스트리밍 데이터에 대한 접근법 중 하나는 데이터가 오는 대로 모으는 임시 발판(staging) 서버를 사용한 다음, 데이터를 배치 적재로 HDFS에 넣는 것이다.
Sqoop은 관계형 데이터베이스로부터 데이터를 불러오는 용도로 설계되었다. Sqoop은 데이터베이스 테이블을 불러오고, 테이블로부터 로우들을 뽑아내기 위한 맵리듀스 잡을 실행하고, 결과 레코드를 HDFS에 쓴다. 데이터 손상으로부터 분리하기 위해 임시 테이블을 사용할 수 있다. 빈 내보내기 테이블로 시작하고 가져오기와 내보내기에 대해 같은 테이블을 사용하지 않는 것이 좋다. SQL 데이터베이스로부터 Hive 데이터 웨어하우스나 HBase 테이블로 데이터를 내보낼 수 있다. Sqoop과 함께 Oozie를 태스크 가져오기와 내보내기 일정을 계획하기 위해 사용할 수 있다. Sqoop은 아파치
Sqoop 프로젝트 페이지로부터 직접 다운로드하거나 Cloudera 것 같은 하둡 배포판의 일부로 다운로드받을 수 있다.
JDBC나 ODBC를 사용한 관계형 데이터베이스와 하둡간 데이터 전송이 느리기 때문에, 많은 벤더들은 고유 도구를 지원하는 빠른 직접 커넥터를 종종 Sqoop 확장을 통해 제공한다. 그 중에서도 직접 커넥터를 제공하는 벤더는 EMC Greenplum, IBM Netezza, Microsoft SQL Server, Microsoft Parallel Data Warehouse (PDW), Oracle and Teradata Aster Data를 포함한다. Quest는 Oracle용 커넥터를 개발했다(Sqoop 프리웨어 플러그인으로 사용 가능한). 더 최근에, Oracle은 Cloudera와 하둡 배포판과 Oracle Big Data Appliance 지원을 제공받는 협력 관계를 맺었다.
잡(job)을 관리하고 질의에 답하라
몇몇 맵리듀스용 잡 스케줄러를 고를 수 있다. Facebook이 개발한 Fair Scheduler는 작은 잡에 대해 빠른 응답 시간을 제공하고, 생산 잡에 대해 서비스 품질을 보장한다. 그것은 하둡 맵리듀스의 기본값으로 설정된 선입선출(FIFO) 스케줄러의 업그레이드이다. Fair Scheduler를 사용하면, 잡들은 풀로 묶이고, 최저한도의 맵 슬롯과 리듀스 슬롯, 그리고 실행되는 잡 개수의 제한을 풀에 배정할 수 있다. 맵 슬롯과 리듀스 슬롯의 최대 할당량을 제한할 수 있는 방법은 없다. (예를 들어 제대로 작성되지 않은 잡이 너무 많은 클러스터 용량을 차지하는 것이 걱정된다면) 그러나 이를 우회할 수 있는 하나의 방법은 각각의 풀에 통제할 수 없는 잡의 연쇄를 일으키지 않을 정도로 충분히 보장된 최소 할당량을 제공하는 것이다.
Yahoo가 개발한
Capacity Scheduler는 큐에 제출된 잡에 우선순위 수준을 배정할 수 있다. 큐 안에서는, 자원을 쓸 수 있게 되면 가장 높은 우선순위를 가진 잡에 배정한다. 잡이 실행되면 이미 배정된 자원 할당량을 되돌리기 위한 끼어들기는 일어나지 않는다.
Yahoo는 작업흐름(workflow) 관리를 위해 Oozie를 개발했다.
Oozie는 HDFS, Pig, 맵리듀스등 하둡에서 실행되는 잡 사이의 의존관계를 조정하는 기능적 확장성이 있고, 규모 확장이 가능하고, 데이터 인식이 가능한 서비스이다.
Azkaban은 하둡 잡이나 다른 오프라인 프로세스를 생성하고 실행시키는 배치 스케줄러를 제공한다. LinkedIn에서는 하루 1조 이상의 관계들의 대용량 데이터 처리 및 저-지연 사이트 제공을 가능하게 하기 위해 대규모 배치 작업을 처리하는 하둡과 NoSQL 키/값 스토리지 엔진에 대한 프로젝트 Voldemort와 Azkaban 오픈소스 작업흐름 시스템을 결합해서 사용한다. LinkedIn은 Azkaban을 오픈 소스 프로젝트로 후원하고 있고, Azkaban github에 코드를 제공하고 있다.
Eclipse를 통합 개발 환경으로 사용하는 조직은 Eclipse IDE 아래 하둡 개발 환경을 설치할 수 있다. 하둡 Eclipse 플러그인으로 Mapper, Reducer, Driver 클래스를 생성할 수 있고, 잡 실행을 모니터링할 수 있다.
Karmasphere Studio는 맵리듀스 잡을 개발, 디버그, 배치, 최적화할 수 있는 그래피컬 작업 환경을 제공한다. Karmasphere는 무료 커뮤니티 에디션과 라이센스 기반 프로페셔널 에디션을 지원한다.
아파치 Pig를 사용하거나 R과 하둡 통합 프로세싱 환경(
RHIPE)에서 R을 사용하여 큰 데이터 셋을 쿼리할 수 있다. 아파치 Hive를 통해 RCFile을 사용한 컬럼식 스토리지 레이아웃뿐만 아니라 큰 데이터 셋에서도 SQL같은 쿼리를 가능하게 할 수 있다.
Tableau와 Cloudera는 Tableau Desktop 버전 7부터 사용 가능한 SQL에서 하둡으로의 인터페이스를 제공하는 Tableau-to-HDFS 직접 커넥터에 대해 제휴했다. 그것은 HDFS에 저장된 XML 오브젝트 지원을 포함한다. Tableau Desktop 안에서, 맵리듀스 잡에 대한 워크로드 파라미터를 설정하도록 커넥터들을 조정할 수 있다. 또한 Tableau의 인-메모리 데이터 엔진을 사용한 빠른 분석이 필요할 때는 데이터를 HDFS에서 Tableau로 가져올 수 있다.
MicroStrategy 9 플랫폼은 이미 구성된 하둡 클러스터나 Amazon Elastic MapReduce와 같은 클라우드 제공 서비스를 위해 애플리케이션 개발자와 데이터 분석가가 HiveQL을 사용하여 쿼리를 제출하고 MicroStrategy 대시보드에서 하둡 데이터를 볼 수 있게 한다. Groupon은 MicroStrategy를 고객 행동에 대한 심도있는 이해 및 광고 효과 평가를 위해 Groupon의 일일 거래를 분석하려고 채택했다. Groupon 직원은 MicroStrategy 기반 리포트와 대시보드를 하둡과 HP Vertica에서 데이터를 분석하기 위해 사용할 수 있다.
SAS는 2012년 2월에 HDFS 지원 계획을 발표했는데, 여기에는 메모리 내 분석을 위해 대용량 메모리가 설치된 블레이드 서버들에서 돌아가도록 설계된, 하드웨어 준비가 된 소프트웨어 패키지가 들어 있다.
Jaspersoft는 하둡에 있는 데이터에 접근하기 위한 3가지 기본 모드를 제공한다. 먼저 Hive를 통해 직접 HiveQL을 통한 SQL-비슷한 질의를 받아들이는 것이다. 이 방식은 배치화된 리포트를 얻고 싶은 IT 직원이나 개발자에게 적합하지만, 현재의 Hive는 꽤 느린 인터페이스기 때문에 빠른 반응시간 응답이 필요한 경우에는 적절하지 않다.
둘째, Jaspersoft는 HBase로의 직접 연결을 제공한다. Jaspersoft는 데이터를 HBase 커넥터를 통해 자신의 인-메모리 엔진에 집어넣는다. 이 방식은 맵리듀스 태스크를 작성하지 않고 하둡에 저장된 데이터를 분석하려는 비즈니스 분석가에게 잘 동작한다.
HBase는 고유 질의 언어가 없기 때문에, 필터링 언어가 없으나 필터링 API는 있다. Jaspersoft의 HBase 커넥터는 StartRow나 EndRow처럼 간단한 것부터 RowFilter, FamilyFilter, ValueFilter, SkipValueFilter와 같이 복잡한 것까지 다양한 하둡 필터를 지원한다. Jaspersoft HBase 질의는 반환되는 ColumnFamily 와/또는 Qualifier를 지정할 수 있다. 몇몇 HBase 사용자들은 굉장히 넓은 테이블을 가지고 있기 때문에, 이 지정은 성능과 사용성을 위해 중요할 수 있다. Jaspersoft HBase 커넥터는 HBase의 쉘을 통해 들어온 데이터나 자바의 기본 직렬화가 사용된 데이터를 위한 역직렬화 엔진(SerDe) 프레임워크와 같이 출하된다. 사용자는 자신이 가진 역직렬 .jars를 플러그인하여 커넥터가 자동으로 HBase의 미가공된 바이트들을 의미있는 데이터 타입으로 변환하도록 할 수 있다.
셋째, Informatica나 다른 ETL 제공자를 통해 Jaspersoft 소프트웨어에서 가능한 관계형 데이터베이스로의 데이터통합 프로세스를 사용할 수 있다. 그리고는 직접 리포트하거나 Jaspersoft의 메모리 데이터베이스 또는 OLAP 엔진을 통해 분석을 수행할 수 있다.
클러스터 밖의 애플리케이션이 파일 시스템에 접근할 수 있게 하려고 한다면, 자바 프로그램의 경우는 자바 API를 사용하면 잘 된다. 예를 들어, 스트림을 열기 위해 java.net.url 객체를 사용할 수 있다. C++, Perl, PHP, Python, Ruby나 그 외의 프로그래밍 언어로 작성된 프로그램에서 파일 시스템에 접근하기 위해서
Thrift API를 사용할 수 있다.
보안을 강화하라
암호없는 Secure Shell(SSH)는 사용 편의상 장점이 있다. - 예를 들어 모든 클러스터 노드를 간단한 명령어로 시작시키고 중지시킬 수 있다 - 그러나 당신의 조직은 암호없는 SSH의 사용을 막는 보안 정책을 가질 수도 있다. 일반적으로, start-all.sh 와 stop-all.sh 명령어는 하둡 평가 혹은 시험 클러스터 가동에는 유용하나, 생산 클러스터에 대해서는 불필요해지거나 사용하지 않고 싶을 것이다.
HDFS의 예전 버전들은 사용자 인증을 위한 견고한 보안을 제공하지 않았다. 올바른 패스워드가 있는 사용자는 클러스터에 접근할 수 있었다. 패스워드를 넘으면, 사용자가 자신이 주장하는 바로 그 사용자인지 검증할 수 있는 인증이 없었다. HDFS에 사용자 인증을 활성화하려면, Kerberos 네트워크 인증 프로토콜을 사용하면 된다. 이것은 Generic Services Application Program Interface(GSS-API)를 통해 Simple Authentication and Security Layer(SASL)을 제공한다. 이 셋업은 위임(Delegation), 잡(Job), 블록 접근(Block Access)을 위한 토큰이 있는 원격 프로시저 호출(RPC) 다이제스트 방식을 사용한다. 이 토큰들 각각은 구조가 비슷하고
HMAC-SHA1에 기반한다. Yahoo는 하둡
Kerberos 인증을 위한 Oozie 작업흐름 관리자 설정 방법을 제공한다.
3단계 Kerberos 티켓 교환 이후, 하둡은 매번 Kerberos 키 배포 센터(KDC)에 접근하지 않고 계속해서 인증된 접근을 허용하기 위해 위임(delegation) 토큰을 사용한다.
Kerberos 인증은 환영할 만한 추가 기능이지만, 그 자체로는 하둡이 엔터프라이즈급 보안에 도달하지 못한다. Andrew Bechere가 BlackHat USA 2010 보안 컨퍼런스에서 발표자료와 백서 "
하둡 보안 설계: 그냥 Kerberos를 추가하라고? 정말?"에서 언급했듯 다음과 같은 보안 약점이 남는다:
- 대칭형 암호 키가 널리 배포된다.
- 잡 트래커, 태스크 트래커, 노드와 Oozie를 위한 몇몇 웹 도구들은 정적 사용자 인증으로 접근 가능한 웹 사용자 인터페이스(UI) 에 의존한다. SPNEGO-기반 웹 인증 플러그인을 더하는 패치 가능한 HADOOP-7119 jira 이슈가 있다.
- 몇몇 구현은 HDFS를 위한 HTTP 프론트엔드를 제공함으로써 대량 데이터 전송에 접근 권한을 주기 위해 프록시 IP 주소와 역할 데이터베이스를 사용한다.
하둡 자체의 제한된 보안을 고려해볼 때, 당신의 하둡 클러스터가 엔터프라이즈 방화벽 뒤에서 근거리 혹은 광역 네트워크에서 운용될 것이라고 해도, 클러스터에 속한 비공개 데이터를 더욱 완벽히 보호하기 위해 클러스터-특정의 방화벽을 고려하고 싶을 수 있다. 이 배치 모델에서, 하둡 클러스터를 IT 인프라 안의 섬으로 생각하라 - 이 섬으로의 모든 연결지점(bridge)을 보안을 위한 모서리(edge) 노드로 고려해야 한다.
클러스터를 둘러싼 네트워크 방화벽에 더해, 데이터베이스 방화벽이나 데이터베이스 활동 감시 제품을 고려할 수 있다. 이런 제품에는 AppSec DbProtect, Imperva SecureSphere and Oracle Database Firewall이 있다. 데이터베이스 방화벽은 데이터베이스로의 접근을 통과, 로그, 경고, 차단, 치환할 것인지에 대한 규칙 기반 결정을 가능하게 한다. 데이터베이스 방화벽은 데이터베이스 감시 제품이라는 더 넓은 소프트웨어 카테고리의 부분집합이다. 대부분의 데이터베이스 방화벽과 활동 감시 제품은 아직 바로 사용할 수 있는 하둡 지원기능이 없다. 데이터베이스 방화벽 벤더나 시스템 통합자의 도움이 필요할 수 있다.
클러스터 밖에서 클러스터를 접근할 수 있도록 인증되고 권한을 부여받은 어플리케이션을 보호하기 위해 다른 보안 조치 또한 필요할 수 있다. 예를 들어, Oozie 작업흐름 관리자를 사용하기로 했다면, Oozie는 모든 하둡 사용자를 대표하여 동작을 수행할 수 있는 승인된 "슈퍼유저" 가 된다. 그래서, 만약 Oozie를 도입하기로 했다면, Oozie와 같이 사용할 추가적인 인증 메커니즘을 고려해야 한다.
어쩌면 위의 몇몇 보안 우려는 Cloudera Enterprise 혹은 Karmasphere Studio처럼, 하둡 데몬에 붙어있는 웹 사용자 인터페이스를 대신해 관리 애플리케이션을 사용하는 기능을 지원한다든가 하는 유료 소프트웨어를 사용하는 것으로 다룰 수 있을지도 모른다. 예를 들어, Cloudera Enterprise 3.5는 현재 버전의 하둡에서 사용 가능한 보안 기능의 설정을 단순화해주는 몇몇 도구를 포함한다. Zettaset(이전 GOTO Metrics)는 사용자-레벨 보안과 감사 트래킹 및 HDFS로의 암호화 옵션 추가 계획을 포함한 보안 향상을 하둡 조정자(Orchestrator)에 묶었다.
하둡 도구 상자에 추가하라
Mike Loukids의 "
데이터 과학이란 무엇인가?"에 언급되었듯이, "만약 무언가 한 곳에서 정보를 모두 처리할 수 있는 플랫폼(one-stop information platform)이라 부를 수 있는 게 있다면, 하둡일 것이다.". 넓은 하둡 생태계는 아파치 프로젝트 및 부프로젝트들, 다른 오픈 소스 도구들, 그리고 독자적 소프트웨어 제공물 등을 통해 툴과 역량에서 다양한 선택을 제공한다. 이는 아래와 같은 것들을 포함한다.
- 직렬화에 대해, 아파치 Avro는 자바 외의 다른 언어로 작성된 네이티브 HDFS 클라이언트를 사용 가능하도록 설계되었다. 다른 가능한 직렬화 옵션에는 구글 Protocol Buffer와 Binary JSON이 있다.
- Cascading은 Concurrent로부터 상업적 지원을 받을 수 있는, 맵리듀스 위에 구현된 오픈소스 데이터 프로세싱 API이다. Cascading은 잡과 작업흐름(workflow) 관리를 지원한다. Concurrent 창립자이자 CTO인 Chris Wensel에 따르면, 모든 XML과 텍스트 문법 없이 단일 라이브러리를 통해 Pig/Hive/Oozie 기능이 제공된다. Nathan Marz는 HDFS로의 가져오기/내보내기를 위한 Cascading 기반 JDBC 도구인 db-migrate를 작성했다. BackType과 그 예전에는 Rapleaf에서, Nathan은 또한 Clojure에서 지원되는 하둡/Cascading 기반 질의 언어인 Cascalog를 작성했다. Multitool은 명령행에서 HDFS나 Amazon S3에 위치한 큰 데이터셋을 "grep", "sed", 조인 가능하게 한다.
- Hadoop User Experience (HUE) 는 브라우저를 통한 "데스크탑-같은" 접근을 제공한다. HUE로, 파일 시스템을 열람하고, 사용자 계정을 생성하고 관리하고, 클러스터 상황을 감시하고, 맵리듀스 잡을 생성하고, Beeswax라는 Hive 프론트엔드를 활성화할 수 있다. Beeswax는 Hive 테이블 생성, 데이터 적재, Hive 질의 실행 및 관리, 결과를 엑셀 형식으로 다운로드 받는 것을 도와주는 마법사를 제공한다. Cloudera는 HUE를 오픈 소스 프로젝트로 공헌했다.
- Pervasive TurboRush for Hive는 Hive가 맵리듀스 대안으로써 데이터흐름(dataflow) 그래프를 사용하여 실행 계획을 생성하도록 허용한다. 그러고 이 그래프들을 클러스터의 장비들에 분산된 Pervasive DataRush를 사용하여 실행한다.
- Pentaho는 데이터 통합, 추출-가공-적재(extract transform load, ETL), 리포트 설계, 분석을 위한 비주얼 디자인 환경과 HDFS, 맵리듀스, Hive, HBase, 더해서 아파치 Cassandra, MongoDB와 통합되는 대시보드를 제공한다. Pentaho는 Kettle ETL 프로젝트를 아파치 버전 2.0 라이센스로 오픈소스화했다.
- Karmasphere Analyst는 하둡 데이터에 Tableau 혹은 Microsoft Excel로의 시각화를 지원하는 Visual SQL 접근을 제공한다. 두번째 제품, Karmasphere Studio는 맵리듀스 잡을 개발, 디버그, 배치, 최적화하기 위한 그래픽 환경을 제공하고, 무료 커뮤니티 에디션 혹은 라이센스-기반 프로페셔널 에디션을 통해 사용 가능하다. Karmasphere는 SSH 터널과 SOCKS 프록시를 통하여 방화벽 뒤의 바로 사용 가능한 하둡 구현을 지원하는데 더해, Amazon Elastic MapReduce와 통합되었고, 연간 사용 계약 대신 EMR-친화적인 선불 옵션을 제공한다.
- Datameer는 그들의 Datameer Analytics 솔루션의 일부분으로 하둡 데이터로 작업하는 분석가를 위한 "스프레드시트 같은" 인터페이스를 제공한다. 추가 기능은 큰 데이터 셋을 적재하고 변환하는 마법사 도구와 analytic workbooks 기반으로 데이터를 시각화하는 대시보드 위젯, 고정밀도 통계를 위한 소수점 이하 32자리까지의 지원, 사용자 집단을 인증하기 위한 외부 LDAP과 액티브 디렉터리와의 통합을 포함한다.
- Google BigTable을 본떠 만든 아파치 Hbase는 HDFS 위에 만들어진 분산 컬럼-지향 데이터베이스이다. HBase로, 큰 데이터 셋에 실시간 읽기와 쓰기 임의 접근을 실행할 수 있다. HBase를 구체화된 뷰들의 백엔드로 사용할 수 있다; Facebook에 따르면, 이것은 실시간 분석을 지원한다.
- HCatalog는 Hive metastore 위에 만들어진 하둡용 메타데이터 도구이다. 이것은 데이터 정의를 위한 명령행 인터페이스와 함께 Pig와 맵리듀스를 위한 읽기와 쓰기 인터페이스를 제공한다. HCatalog는 Pig, Hive, 맵리듀스를 위한 공유 스키마와 데이터 모델을 제공한다. HCatalog는 아파치 프로젝트로 승격되었다.
- Hadoop Online Prototype(HOP)는 데이터가 태스크 간에 그리고 잡 간에 파이프라인되는 것을 허용하는 하둡 맵리듀스의 수정된 버전이다. 이것은 더 나은 클러스터 활용과 병렬성 증가를 가능하게 한다. 그리고 다음과 같은 새 기능을 허용한다: 온라인 집합 연산(aggregation) (잡이 실행될 때 해답 근사치), 스트림 프로세싱(연속으로 실행되는 맵리듀스 잡, 새 데이터가 오자마자 처리). HOP는 현 단계에서는 완제품 상태가 아닌 개발 프로토타입이라는 점에 주의하라.
- VMware는 2012년 2월에 그들의 Spring 개발 프레임워크(SpringSource 합병으로 얻은)를, Spring 컨테이너를 통한 맵리듀스, Streaming, Hive, Pig, Cascading 잡 지원과 함께 "Spring Hadoop" 으로 확장했다.
하둡의 느슨하게 결합된 아키텍처의 장점 중 하나라면 HDFS나 맵리듀스와 같은 구성요소를 대체할 수 있다는 것이다. 느슨하게 결합된 데이터-중심 아키텍처로서, 하둡은 조립식 구성요소를 지원한다. 2011년 3월 InformationWeek 기사에 Rajive Joshi가 언급한 것처럼, "데이터-중심 설계의 핵심은 데이터와 동작을 분리하는 것이다. 그러면 데이터와 데이터 전송 구조가 주된 조직화 구조가 된다." 이것은 하둡 구성요소간 통합 작업 없이 완벽한 플러그 앤 플레이가 된다는 이야기가 아니다. (제안된 아파치 Bigtop 프로젝트가 이 분야에 도움이 될지도 모른다), 모든 조직이 똑같은 하나로 된 소프트웨어 스택을 사용할 필요가 없다는 것이다.
하둡 스택 구성요소를 다른 방식으로 대체하는 제품을 내놓은 몇몇 신생 기업들이 최근 급부상했다. 다음과 같은 것들이 있다:
하둡의 시장 점유 증가 추세로 보자면, 더 많은 하둡의 대안이나 경쟁자의 등장이 눈에 띄기 시작하는 것은 놀랍지 않다. 여기에는 Spark와 LexisNexis HPCC 등이 있다.
Spark는 UC Berkeley AMP 랩에서 개발되었고, 스팸 필터링, 자연어 처리, 도로 통행량 예측을 위한 버클리의 몇몇 연구 그룹에 의해 사용되었다. AMP Lab은 기계학습 반복적 알고리즘과 상호작용형 데이터 마이닝을 위해 Spark를 개발했다. 온라인 영상 분석 서비스 제공업체 Conviva는 Spark를 사용한다. Spark는 BSD 라이센스의 오픈 소스이다. Spark는 하둡 응용 프로그램 또한 실행할 수 있는 Mesos 클러스터 관리자 위에서 실행된다. Mesos의 사용자에는 Conviva, Twitter, UC Berkeley 등이 있다. Mesos는 2011년 1월 아파치 Incubator에 합류했다.
2011년 6월, LexisNexis는 하둡 대안으로 고성능 컴퓨팅 클러스터를 발표했다. HPCC Systems는 지원, 교육, 컨설팅을 받을 수 있는 엔터프라이즈 에디션과 함께 무료 커뮤니티 버전을 위한 계획을 발표했다. Sandia National Laboratories는 페타바이트 단위의 데이터를 정렬하고 상관 관계를 찾고 가설을 세우기 위해 데이터 분석 슈퍼컴퓨터 플랫폼이라는 HPCC의 선도 기술을 사용한다. LexisNexis에 따르면, HPCC Systems 설정은 하둡 클러스터와 같은 처리 성능을 제공할 때 더 적은 노드로 가능하고, 몇몇 성능 시험 테스트에서 더 빠르다.
그러나, 어떤 타입의 준구조적, 비구조적, 미가공 데이터 분석이 LexisNexis/HPCC System에서 더 빠르게 수행되거나 더 적은 노드로 수행되는지는 불분명하다. LexisNexis는 회사들과 공헌자들의 생태계가 아파치 하둡 커뮤니티가 이루어낸 것 같은 활기를 가지기 위해 애써야 할 것이다. 그리고 그들의 HPCC 기술은 LexisNexis 밖에서 널리 쓰이지 않고, 정부나 학계에서만 가끔 쓰이는 ECL 프로그래밍 언어를 사용한다.
정리하면서
하둡은 이질적 소스로부터의 거대하고 다양한 준구조적, 비구조적, 미가공 데이터 볼륨을 저장, 처리, 분석하기 위한 정보 플랫폼으로 성숙하고 있다. 하둡을 시작하려면:
- 무료 배포판 중 하나를 독립 실행이나 의사 분산 모드로 평가하라.
- Tom White의 "Hadoop: The Definitive Guide, Second Edition"을 참고하고, Cloudera, Hortonworks 혹은 아파치 하둡 위키의 지원 페이지에 있는 다른 서비스 제공자로부터 하나 이상의 강좌 수강을 고려하라.
- 구성된 클러스터에서는, 네임노드, 세컨더리 네임노드, 맵리듀스 자원 관리자에 대해서 별도의 엔터프라이즈급 서버를 사용하라. .
- 랙 감지, 파일 시스템 검사, 로드 밸런싱에 대한 운영 팁을 기억하라.
- 사용자 인증, edge 노드 보안 방화벽, 다른 보안 정책으로 보안을 강화하라.
자신의 하둡 경험에 기반해 어떤 배치 팁, 주의, 혹은 모범 사례를 더하거나 지적하겠는가?
Val Bercovici, Michele Chambers, Julianna DeLua, Glynn Durham, Jeff Hammerbacher, Sarah Sproehnle, M.C. Srivas, and Chris K. Wensel 에게, 원고 초안을 평해준 것에 감사한다.
